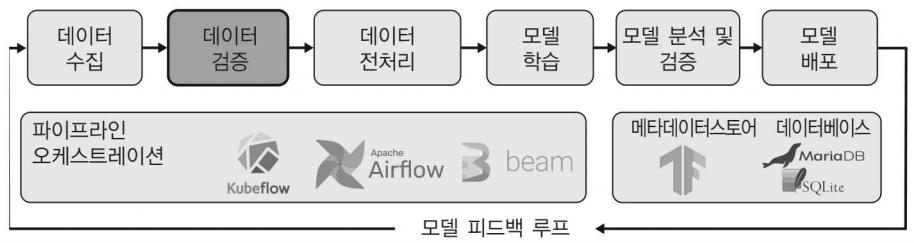
이번 포스팅부터는 머신러닝 파이프라인의 2번째 단계인 데이터 검증에 대해 알아보겠다.
머신러닝에서는 데이터셋의 패턴에서 학습하고 이를 일반화 하려고 한다 . 따라서 데이터는 머신러닝 워크플로에서 가장 중요한 역할을 하며,데이터의 품질은 머신러닝 프로젝트 성공의 핵심 요소이다.
또한 시간이 오래 걸리는 전처리 및 학습 단계에 도달하기 전에 머신러닝 파이프라인에 들어오 는 데이터의 변화를 포착하므로 매우 중요한 체크포인트이다.
위와 같은 이유로 데이터 검증이 필수이다. 데이터 검증의 의미는 아래와 같이 확인할 수 있다.
- 데이터 이상치 확인
- 데이터 스키마 변경 유무 확인
- 새 데이터셋의 통계와 이전 학습 데이터셋의 통계의 일치 여부 확인
TFDV
텐서플로는 데이터 검증을 지원하는 도구인 TFDV를 제공합니다. . TFDV를 사용하면 앞서 언급한 분석 유형 (ex. 스키마 생성 및 기존 스키마에 대한 새 데이터 검증)을 수행할 수 있다. 또한 [그림 1]와 같이 시각화를 제공한다.
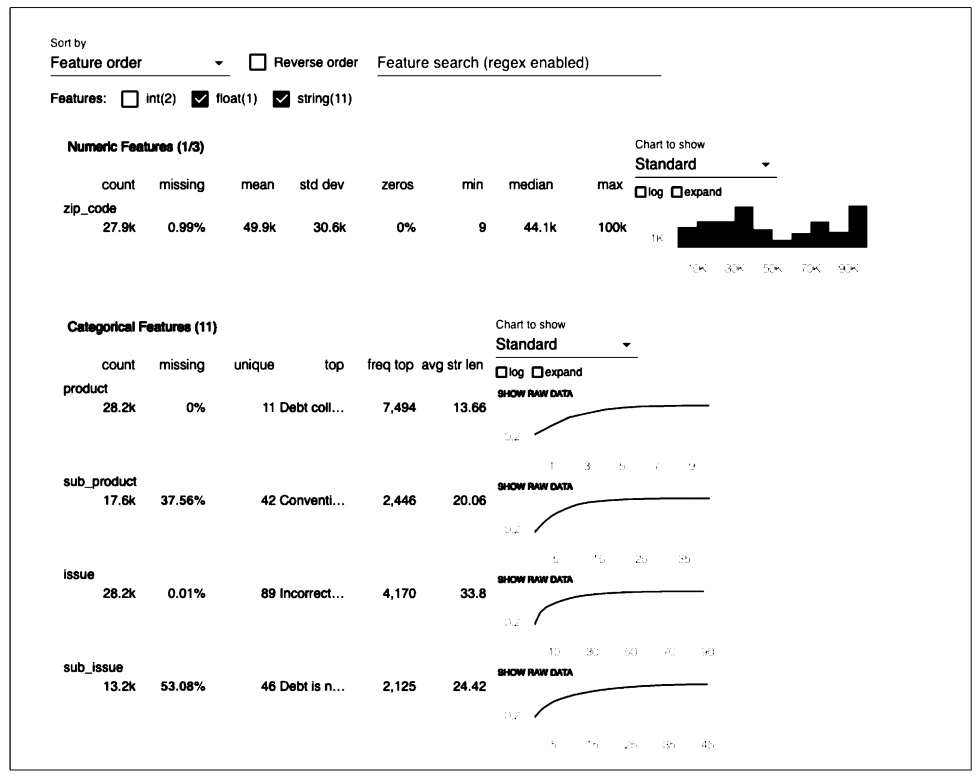
바로 TFDV를 활용한 실습을 진행해보겠다.
1) 설치
TFX 패키지를 설치했을 때 TFDV도 함께 설치되었다. 다만 TFDV만 사용하 려면 다음 코드를 사용하여 설치하길바란다.
pip install tensorflow-data-validation설치 후에는 데이터 검증 컴포넌트를 머신러닝 워크플로우에 통합하거나 주피터 노트북에서 시각적으로 데이터를 분석할 수 있다.
2) 요약 통계 생성
import tensorflow_data_validation as tfdv
stats = tfdv.generate_statistics_from_csv(
data_location='/data/consumer_complaints.csv',
delimiters',')다음 코드를 사용하여 매우 비슷한 방법으로 TFRecord 파일에서 피처 통계를 생성할 수 있다.
stats = tfdv.generate_statistics_from_tfrecord(
data_location=’/data/consumer_complaints.tfrecord')
이전 포스트에서 TFRecord 파일을 생성하는 방법을 알아봤는데 두 TFDV 방법은 모두 최솟값, 최댓값, 평균값을 포함하여 각 피처에 관한 요약 통계를 저장하는 데이터 구조를 생성한다.
데이터 구조는 아래와 같다.
datasets {
num_examples: 66799
features {
type: STRING
string_stats {
common_stats {
num_non_missing: 66799
min_n니m_values: 1
max_num_valiies: 1
avg_num_values: 1.0
num_values_histogram {
buckets {
low_value: 1.0
high_value: 1.0
sample_count: 6679.9
}}}}}}
3) 데이터에서 스키마 생성
schema = tfdv.infer_schema(stats)tfdv.infer_schema는 텐서플로에서 정의한 스키마 프로토콜 버퍼를 생성한다.
또한 주피터 노트북에서 단일 함수로 스키마를 표시할 수도 있다.
tfdv.display_schema(schema)
이제 정의한 스키마를 사용해 학습이나 평가 데이터셋을 비교하거나 데이터셋에 모델에 영향을 주는 문제가 있는지 확인할 수 있다.
여기서 생성한 스키마는 현재 데이터셋이 미래의 모든 데이터를 정확히 대표한다고 가정하기때문에 필요한 스키마가 아닐 수 있다. 또한 이 데이터셋의 모든 학습 예제에 피처가 있을 때 필수 항목으로 표시되지만 실제로는 선택 사항일 수 있다.
This post was written based on what I read and studied the book below.
https://www.oreilly.com/library/view/building-machine-learning/9781492053187/
댓글