이전 '데이터 검증(1)' 에서는 데이터의 요약 통계와 스키마를 생성하는 방법을 알아봤다.
데이터를 설명해주지만, 잠재적은 문제를 발견하지 못하기 때문에 이번에는 TFDV가 데이터에서 문제를 발견하는데 어떤 기능이 있는지 살펴보겠다.
1) 데이터셋 비교
머신러닝 모델을 학습하기 전에 학습 데이터셋에 대한 검증 데이터셋의 대표성을 확인하려고 가정했을 때 검증 데이터는 학습 데이터 스키마를 준수하는지, 피처값의 유의미한 수가 누락되었는지 등을 TFDV에서 확인할 수 있다.
아래와 같이 두 데이터셋을 로드한 후 시각화할 수 있다.
train_stats = tfdv.generate_statistics_from_tfrecord(
data_location=train_tfrecord_filename)
val_stats = tfdv.generate_statistics_f rom_tfrecord(
data_location=val_tfrecord_filename)
tfdv.visualize_statistics(l.hs_statistics=val_stats, rhs_statistics=train_stats_>
lhs_name='VAL_DATASET', rhs_name='TRAIN_DATASET')
또한 아래 코드를 사용하여 이상치를 탐지 할 수 있다.
anomalies = tfdv.validate_statistics(statistics=val_stats, schema=schema)tfdv.display_anomalies(anomalies)
다음 코드는 디폴트로 설정된 이상치 프로토콜을 보여준다. 여기에는 머신러닝 워크플로를 자동화하는 데 필요한 정보들이 많이 포함되있다.
anomaly_info {
key: "company"
value {
description: "The feature was present in fewer examples than expected."
severity: ERROR
short_description: "Column dropped"
reason {
type: FEATURE_TYPE_LOW_FRACTION_PRESENT
short_description: "Column dropped"
description: "The feature was present in fewer examples than expected."
}
path {
step: "company"
}
}
}
2) 스키마 업데이트
우선 스키마를 직렬화된 위치에서 로드하겠다.
schema = tfdv.load_schema_text(schema_location)그 후에 특정 피처의 min_fraction 값을 90%로 설정한다.
sub_issue_feature = tfdv.get_feature(schema, * sub_issue')
sub_issue_feature.presence.min_ffaction = 0.9
스키마가 검증되면 다음과 같이 스키마 파일을 직렬화하여 다음 위치에 생성한다.
tfdv.write_schema_text(schema, schema_location)그리고 통계를 다시 확인하여 업데이트된 이상치를 확인해야 한다.
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
자, 이런 방식으로 이상치를 데이터셋에 적합하도록 조정할 수 있다.
3) 데이터 스큐 및 드리프트
TFDV는 두 데이터셋의 통계 간의 큰 차이를 감지하는 내장 '스큐(Skew) 비교기)를 제공한다. 이는 'Skew: 평균 근처에 비대칭적으로 분포된 데이터셋' 과 같은 통계적 정의가 아니다. TFDV서는 두 데이터셋의 service_statistics 간의 차이에 대한 L-infinity Norm으로 정의가 된다. 두 데이터셋 간의 차이가 특정 피처에 대한 L-infinity Norm의 임곗값을 초과한다면, TFDV는 이전에 정의한 이상치 감지를 사용하여 이상치로 강조한다.
L-infinity Norm
L-infinity Norm은 두 벡터 상이ㅢ 차이를 정의하는 데 사용하는 표현식이다. (이 포스팅에서는 서비스 통계량을 의미). 또한 L-infinity Norm은 벡터 항목의 최대 절댓값이다.
예를 들어, 벡터 [3, -10, -5]의 L-infinity Norm은 10이다. Norm은 벡터를 비교하는 데 자주 사용한다. 벡터 [2, 4, -1]과 [9, 1, 8]을 비교하려면 먼저 둘의 차이인 [-7, 3, -9]를 계한한 다음 이 벡터의 L-infinity Norm인 9를 계산한다.
TFDV에서 두 벡터는 두 데이터셋의 요약 통계이다. 반환되는 Norm은 두 통계량 사이의 가장 큰 차이이다.
다음 코드는 데이터셋 간의 왜곡을 비교하는 방법을 보여준다.
tfdv.get_featu re(schema,
'company *).skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(statistics=train_stats,
schema=schema
serving_statistics=serving_stats)
각각 다른 날 수집한 두 학습 데이터셋과 같이 동일한 유형의 두 데이터셋의 통계를 비교하는 drift_comparator을 사용해 보겠다.
스큐 예저와 마찬가지로, 비교할 피처에 대해 drift_comparator를 정의해야 한다. 그런 다음 기준 및 비교 대상 데이터셋 통계 (ex. 어제 수집한 데이터셋과 오늘의 데이터셋)를 인수로 넣고 validate_statistics를 호출할 수 있다.
tfdv.get_feature(schema,
'company*).drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(statistics=train_stats_today,
schema=schema,
previous_statistics=\
train_stats_yesterday)
skew_comparator와 drift_comparator의 L-infinity Norm은 데이터 입력 파이프라인에 문제가 있음을 알려주는 데이터셋 간의 큰 차이를 보여주는 데 유용하다. 그리고 L-infinity Norm은 단일 숫자만 반환하므로 스키마가 데이터셋 간의 변동을 탐지하는 데도 유용하다.
4) 편향된 데이터셋
입력 데이터셋에는 편향(bias)이라는 잠재적인 문제도 있다. 우리는 편향을 현실 세계와 동떨어진 데이터로 정의한다. 공정성은 서로 다른 그룹의 사람들에게 이질적인 영향을 미치는 모델의 예측이다. 편향은 여러 가지 방법으로 데이터에 침투합니다. 데이터셋은 항상 실제 환경의 부분 집합이 며, 우리는 모든 세부 정보를 캡처할 수는 없다. 실제 세계를 표본으로 추출하는 방법은 어 떤 식으로든 항상 편향된다.
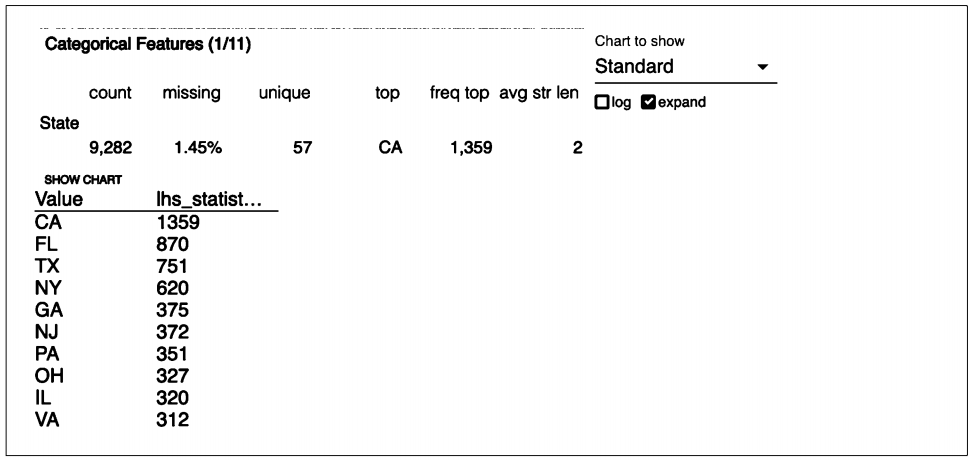
선택편향 은 우 리 가 확 인 할 수 있 는 편향 유형이다. 데이터셋의 분포가 실제 데이터 분포와 같지 않은 상황인거다. 앞에서 설명한 TFDV의 통계 시각화를 사용하여 선택 편향을 확인할 수 있다. 예를 들어 데이터셋에 범주형 피처로 Gender가 포함되면 값이 남성 범주에 치우치지 않았는지 확인할 수 있다. 소비자 불만 사항 데이터셋에는 State가 범주형 피처로 포
함된다. 이상적으로는 여러 미국 주에 걸친 데이터 수의 분포가 각 주의 모집단을 반영해야 한다.
하지만 아래 시각화한 그림에서 그렇지 않음을 알 수 있다. 예를 들어 3위인 텍사스는 2위 플로리다보다 인구가 더 맣ㄴ다. 데이터에서 발견한 이런 편향이 모델의 성능을 해칠 수 있다면, 다시 돌아가서 더 많은 데이터를 소집하거나 오버/언더샘플링하여 정확한 분포를 얻어야 한다.
5) 데이터 슬라이싱
선택한 피처에서 데이터셋을 슬라이싱하여 데이터 편향을 확인할 수도 있다.
여러 미국 주의 데이터를 예로 들어보겠다. 다음 코드를 사용하여 캘리포니아에서만 통계를 얻도록 데이터를 슬라이싱할 수 있다.
from tensorflow_data_validation.utils import slicing_util.
# 피처값은 이진수 값의 목록으로 제공해야 합니다.
slice_fnl = slicing_util.get_feature_val.ue_slicer(
features={'state': [b'CA']})
slice_options = tfdv.StatsOptions(slice_functions=[slice_fnl])
slice_stats = tfdv.generate_statistics_from_csv(
data_Location='data/consumer_c아nplaints.csv',
stats_options=slice_options)몇 가지 헬퍼 함수를 사용해 슬라이싱한 통계를 시각화 해보겠다.
from tensorflow_metadata.proto.v0 import statistics_pb2
def display_slice_keys(stats):
print(list(map(lambda x: x.name, slice_stats.datasets)))
def get_sliced_stats(stats, slice_key):
for sliced_stats in stats.datasets:
if sliced_stats.name == slice_key:
result = statistics_pb2.DatasetFeatureStatisticsList()
result.datasets.add().CopyFrom(sliced_stats)
return result
print('Invalid Slice key')
def compare_sl.ices(stats, slice_keyl, slice_key2):
lhs_stats = get_sliced_stats(stats, slice_keyl)
rhs_stats = get_sliced_stats(stats, slice_key2)
tfdv.visualize_statistics(lhs_stats, rhs_stats)다음 코드를 사용해 결과를 시각화할 수 있다.
tfdv.visualize_statistics(get_sliced_stats(slice_stats, 'state_CA'))이제 캘리포니아의 통계를 전체 결과와 비교해보겟다.
compare_slices(slice_stats, 'state_CA', 'All Examples')
이상 TFDV의 기능을 이용하여 데이터를 검증하는 다양한 방법들에 대해 알아보았다.
다음 포스팅에서는 TFDV를 컴포넌트로써 머신러닝 파이프라인에 통합하는 방법을 올려보겠다.
This post was written based on what I read and studied the book below.
https://www.oreilly.com/library/view/building-machine-learning/9781492053187/
댓글