연관규칙 분석 (Association Analysis)은 두 개 이상의 거래나 사건에 포함되어 있는 항목(아이템)들 간의 관련성을 파악하는 탐색적 데이터 분석방법이다. 이 연관규칙 분석을 고객이 구매한 상품 항목에 적용할 경우 장바구니 분석 (Market Basket Analysis)이라 부른다. 연관규칙 분석은 거래 데이터로부터 상품 간 혹은 서비스 간의 연관성 정도를 측정하여 연관규칙 (Associative Rule)을 도출하는데, 연관규칙은 다음과 같이 표현한다.
if 절은 ‘선행조건 (antecedent)’, then 절은 ‘후행조건 (Consequent)’이라고 한다. 예를 들어, 식료품 마트의 판매 데이터에서 발견된 ‘{양파, 아스파라거스} ⇒ {소고기}’ 규칙은 고객이 양파와 아스파라거스을 함께 구매하면 고기도 살 가능성이 높다는 것을 의미한다. 연관성 규칙에서 선행과 후행은 공통원소가 없는 항목들의 집합이어야 한다. 가령, ‘if 농구공, 배구공 then 탁구공’이어서는 안 된다.
데이터에 시간적 순서가 있는 상황에서 연관성 규칙을 생성하면 순차연관규칙 분석 (Sequence Analysis 또는 Sequential Association Analysis)이 된다. 순차연관규칙 분석에서 도출되는 순차연관규칙 ‘A B (if A, then B)’에서는 에 대한 구매가 B 에 대한 구매보다 시간적으로 선행하는 것을 의미한다.
아쉽게도 파이썬에서는 아직 순차연관규칙 분석을 직접 지원하는 모듈이나 함수가 존재하지 않는다. 따라서, 이번 게시글에서는 순차연관규칙 분석을 따로 논의하지는 않는다. 다만, 시간적 순서가 존재하는 구매 데이터에 일반적인 연관규칙 분석을 적용한 후, 도출된 규칙에서 AB & B⇒A 와 같이 양방향 규칙이 존재할 경우 시간적 제약조건에 따라 규칙을 제거 및 정렬함으로써 순차연관성 규칙을 추출할 수 있다.
연관규칙 분석은 비교적 간단한 계산 방법으로 보이지 않는 구매패턴까지 탐색할 수 있고, if - then 형태의 직관적인 규칙으로 도출되어 협업에서 쉽게 활용 가능하다는 장점이 있다. 이러한 특징으로 유통업에서 교차판매 전략, 상품진열 레이아웃, 라이브러리 상품 기획 등 다양한 용도로 사용되었으며, 분석 대상의 항목을 상품이 아니라 소비자의 행동이나 이벤트 등으로 확장하면 다양한 서비스 영역에서 응용할 수 있다.
연관규칙 분석은 분석 항목 증가에 따른 연산 부하가 급격하게 늘어나는 편이며, 분석 항목 외의 중요한 비즈니스 요소를 고려할 수 없다는 단점이 존재한다. 연관규칙 분석의 장단점을 요약하면 다음과 같다.
[표 1] 연관규칙 분석의 장단점
| 장점 | 데이터에 내재된 많은 규칙을 찾을 수 있다. |
| 실무에서 쉽게 활용할 수 있는 형태의 규칙을 생성한다. | |
| 연관규칙을 찾는 계산 방법이 단순하다. | |
| 단점 | 분석 항목이 많아지면 연산 시간이 급격하게 증가한다. |
| 분석 항목 외의 다양한 비즈니스적 요소를 고려하기 어렵다. | |
| 도출된 연관규칙에 대해 합리적인 논리와 배경을 설명하기 어렵다. |
지지도, 신뢰도, 향상도
연관규칙 분석을 통해 도출되는 연관규칙의 선정기준과 성능은 지지도 (Support), 신뢰도 (Confidence), 향상도 (Lift)를 통해 평가한다. 이 세 가지 지표를 AB (if A, then B)라는 가상의 규칙에 적용하여 설명해보자.
지지도
지지도는 개별 변수에 대한 지지도와 규칙에 대한 지지도로 구분할 수 있다. 특정 변수에 대한 지지도 (Support)는 전체 거래 중에서 해당 변수을 포함하는 비율을 의미하며 다음과 같이 표현할 수 있다.
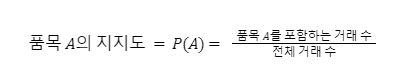
만약, 지지도를 규칙에 대해 적용하고자 한다면, A와 B에 대한 지지도를 의미하며 두 가지 품목이 함께 거래된 비율을 의미하므로 다음과 같이 표현할 수 있다.

신뢰도
신뢰도 (Confidence)는 품목 A가 포함된 거래 중에서 품목 B가 포함될 확률을 의미한다. 즉, 품목 A에 대한 품목 B의 조건부 확률이며, 다음과 같이 표현할 수 있다.

향상도
도출된 연관규칙의 지지도와 신뢰도가 높아도 우연에 의해 나타난 규칙일 수 있으므로 향상도라는 보조적인 지표를 살펴볼 필요가 있다. 향상도 (Lift)는 두 품목(A와 B)이 동시에 구매되는 확률과 후행조건(품목 B)이 독립적으로 구매된 확률을 비교해 봄으로써 도출된 규칙이 우연에 의해 나타난 것인지 실제 연관성이 존재하여 나타난 것인지 판단하는 데 도움을 준다. 규칙 AB 에 대한 향상도는 다음과 같이 표현할 수 있다.

향상도의 값이 1이면 두 품목은 상호 독립적인 관계라는 의미이며, 1보다 크면 양의 상관관계, 1보다 작으면 음의 상관관계를 갖는다는 의미이다. 즉, 향상도가 1에 가깝다면 신뢰도와 지지도가 높다 하더라도 이는 우연에 의해 연관성이 높게 나타났을 가능성이 있다.
Apriori 알고리즘
Apriori 모형은 주어진 거래 이력을 바탕으로 빈발 항목 세트 (Frequent Item Set)를 생성하고, 이를 기반으로 연관규칙을 찾는 알고리즘이다. 주어진 거래 이력의 모든 항목에서 가능한 모든 규칙을 구하면 매우 많은 규칙을 고려해야하므로 빈발 항목 세트를 우선적으로 도출하고 규칙을 생성하면 훨씬 효율적이고, 빠른 연산이 가능하다.

[그림 ] Apriori 모형의 개념도
Apriori 알고리즘의 규칙 생성 과정을 구체적으로 설명하면 다음과 같다.
최소 지지도를 설정한다.
예시를 위해 아래와 같은 구매 데이터가 존재한다고 가정하고, 최소 지지도는 50%라고 설정해보자.
| 고객 | 품목 |
| 1 | A C D |
| 2 | B C E |
| 3 | A B C E |
| 4 | B E |
최소 지지도를 바탕으로 빈발 항목 세트를 구성한다.
상기 구매 데이터에서 존재하는 모든 하위 데이터 세트는 (A, B, C, D, E, AB, AC, AD, AE, BC, BD, BE, CD, CE, DE, ABC, ABD, ...) 등이지만 그 중에서 지지도가 50% (= 2/4) 이상인 항목들로 구성된 빈발 항목 세트는 다음과 같다.
| 품목 | 지지도 |
| A | 2/4 |
| B | 3/4 |
| C | 3/4 |
| E | 3/4 |
| AC | 2/4 |
| BC | 3/4 |
| BE | 3/4 |
| CE | 2/4 |
| BCE | 2/4 |
빈발 항목 세트를 통해 가능한 후보 규칙들을 생성한다.
상기 빈발 항목 세트에서 개별 품목들 A, B, C, E 등은 규칙의 의미가 없으므로 두 개 이상으로 구성된 품목 세트인 AC, BC, BE, CE, BCE 등으로부터 후보 규칙을 도출한다. BCE의 경우 가능한 후보 규칙은 B → CE, C → BE, E → BC, BC → E, BE → C, CE → B 등 6개의 후보 규칙이 생성될 수 있다.
도출된 후보 규칙들에 대해서 지지도, 신뢰도 등의 기준을 통해 적합한 연관규칙들을 선별해낸다.
앞서 BCE를 통해 도출된 6개의 후보 규칙을 예로 들었을 때 각 규칙별 지지도와 신뢰도는 다음과 같다. 만약, 신뢰도 기준을 80%라고 한다면 최종 선별된 연관규칙은 CE🡪B가 된다.
| 후보규칙 | 지지도 | 신뢰도 |
| B → CE | 2/4 | 2/3 |
| C → BE | 2/4 | 2/3 |
| E → BC | 2/4 | 2/3 |
| BC → E | 2/4 | 2/3 |
| BE → C | 2/4 | 2/3 |
| CE → B | 2/4 | 2/2 |
This post was written based on what I read and studied the book below.
http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791195511747
댓글