추천시스템의 전문가가 되기 위해 지금까지, 그리고 미래에 공부할 내용들을 소개하는 카테고리를 만들었다.
이 카테고리에 앞으로 작성될 모든 게시글에서 사용할 데이터셋을 소개하고 설명하겠다.
MovieLens
Movielens는 영화 추천 시스템을 연구하는 데 사용되는 가장 널리 사용되는 온라인 영화 데이터셋 중 하나이다. Movielens 데이터셋은 대규모 사용자 행동 데이터를 제공하며, 사용자가 영화를 어떻게 평가하고 어떤 영화를 선호하는지 등을 이해하는 데 매우 유용하다.
Movielens 데이터셋은 University of Minnesota twin cities에서 유지관리된다.

ml-latest-small.zip (size: 1 MB)
ml-latest-small 데이터셋은 Movielens 데이터셋의 작은 버전이다. 이 데이터셋은 2018년 9월에 마지막으로 업데이트된 것으로 보이고 9,742개의 영화에 대한 100,836개의 사용자 평가 및 3,683개의 태그 적용 기록을 포함하고 있다. 또한, 이 데이터는 610명의 사용자가 기록했다.
데이터셋은 총 4개의 CSV 파일로 구성되어 있다.
1. movies.csv
- movieId (int): 영화 고유 ID
- title (string): 영화 제목 및 개봉 연도
- genres (string): 영화 장르 (파이프('|')로 구분)
movies_df = pd.read_csv('ml-latest-small/movies.csv')
print('Movies data shape:', movies_df.shape)
print(movies_df.head())
genres_count = movies_df['genres'].str.split('|').apply(pd.Series).stack().value_counts()
genres_count.plot(kind='bar')
plt.title('Number of Movies by Genre')
plt.xlabel('Genre')
plt.ylabel('Number of Movies')
plt.show()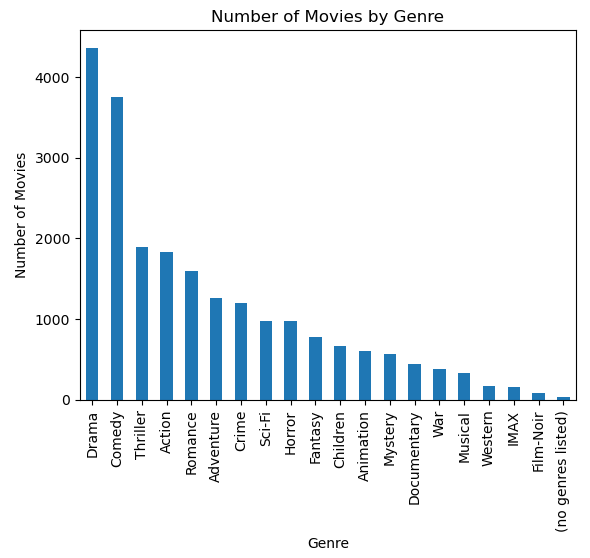
2. ratings.csv
- userId (int): 사용자 고유 ID
- movieId (int): 영화 고유 ID
- rating (float): 사용자가 영화에 대해 매긴 평점 (0.5 ~ 5.0 점)
- timestamp (int): 사용자가 평점을 매긴 시간 (UTC)
ratings_df = pd.read_csv('ratings.csv')
print('Ratings data shape:', ratings_df.shape)
print(ratings_df.head())
ratings_df['rating'].hist()
plt.title('Distribution of Ratings')
plt.xlabel('Rating')
plt.ylabel('Number of Ratings')
plt.show()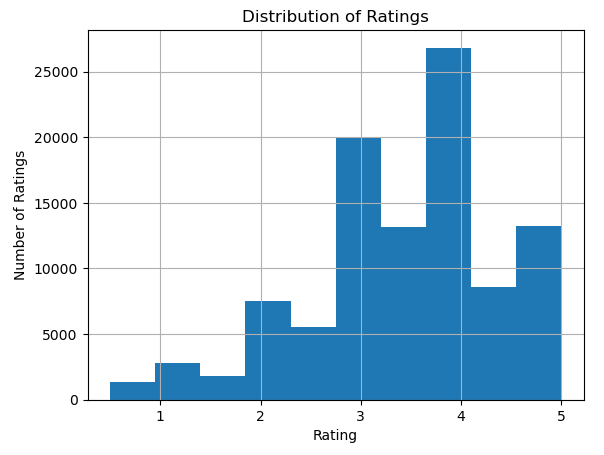
3. tags.csv
- userId (int): 사용자 고유 ID
- movieId (int): 영화 고유 ID
- tag (string): 사용자가 영화에 적용한 태그
- imestamp (int): 사용자가 태그를 적용한 시간 (UTC)
tags_df = pd.read_csv('tags.csv')
print('Tags data shape:', tags_df.shape)
print(tags_df.head())
tag_count = tags_df['tag'].value_counts().head(10)
tag_count.plot(kind='bar')
plt.title('Top 10 Tags')
plt.xlabel('Tag')
plt.ylabel('Number of Tags')
plt.show()
4. links.csv
- movieId (int): 영화 고유 ID
- imdbId (int): 영화의 IMDb ID
- tmdbId (int): 영화의 TMDB ID
links_df = pd.read_csv('ml-latest-small/links.csv')
print('Links data shape:', links_df.shape)
print(links_df.head())
links.csv 파일은 영화 데이터를 다른 영화 데이터베이스와 연결하기 위해 주로 사용되므로 여기선 사용할 필요가 없다.
자 이제 이 데이터셋을 통하여 추천시스템 관련 내용을 차근차근 포스팅 해보겠다.
댓글