텍스트 마이닝 (Text Mining)이란 비정형 텍스트 데이터에서 의미 있는 정보를 추출하고, 가공하는 일련의 분석과정을 의미하며, 이를 통해 분석자는 원하는 정보나 생각하지 못한 새로운 정보를 추출하여 통찰을 얻을 수 있다. 가령, 소비자 리뷰 텍스트 데이터를 통해서 제품에 대해 전반적으로 어떤 기대 혹은 불만을 갖고 있는지 혹은 소비자가 브랜드에 대해 갖고 있는 전반적인 이미지를 파악함으로써 마케팅 전략을 세우는 데 도움을 줄 수 있다.
텍스트 마이닝이 다루는 데이터는 소위 빅 데이터 (Big Data)인데, 엄밀하게 말해 빅 데이터는 세 가지 유형으로 나눌 수 있다 [그림 1 참조]. 우선, 앞서 우리가 다루어왔던 정형 데이터 (Structured Data)는 구조화되어 있는 데이터를 통칭하는 것으로 다양한 데이터가 포함된다. 반정형 데이터 (Semi-Structured Data)는 형태 (Schema)는 있지만, 연산이 불가능한 형태의 데이터로 보통 XML, HTML, JSON, 로그 형태의 데이터(웹 로그, 센서 데이터) 등을 의미한다. 마지막으로 비정형 데이터 (Unstructured Data)는 형태가 없으며, 연산이 불가능한 데이터로 영상, 이미지, 텍스트 데이터 그리고 트위터, 페이스북과 같은 소셜 네트워크 서비스 (Social Network Service, SNS)에서 얻을 수 있는 소셜 데이터 등을 의미한다.
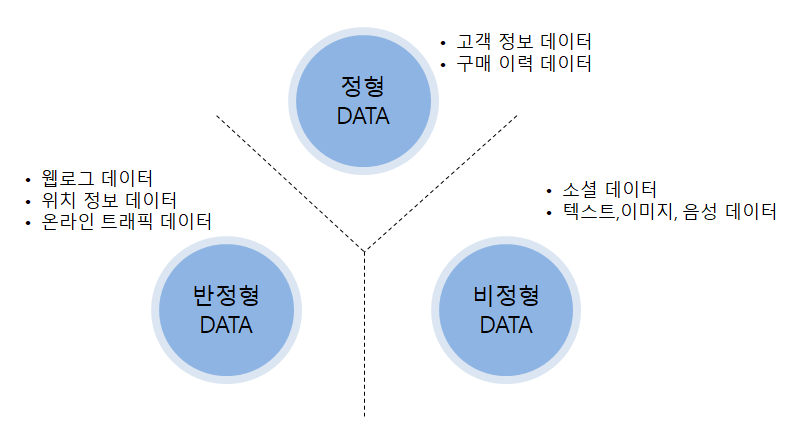
[그림 1] 데이터 유형
앞선 포스팅에서는 정형화된 형태의 데이터를 이용하여 분석을 수행했기 때문에 전처리 과정은 데이터 정제, 정규화, 병합 정도에 그쳤지만, 텍스트 마이닝은 비정형 데이터를 다루기 때문에 비정형 데이터를 정형화된 형태로 바꾸는 과정이 필요하다. 이러한 비정형 데이터의 전처리 과정 대부분은 자연어 문서로부터 의미 있는 정보를 추출하는 데 집중되어 있다.
일반적으로 텍스트 마이닝의 과정은 다음과 같이 크게 4단계의 과정을 거친다.

[그림 2] 텍스트 마이닝 단계
텍스트 수집
텍스트 문서를 수집하는 단계로서 메일, 뉴스, 블로그, SNS 등 다양한 원천으로부터 텍스트 문서의 수집이 가능하다. 이러한 대량의 텍스트 데이터는 웹 페이지의 특정 부분의 내용을 추출하는 웹 스크래핑 (Web Scraping)을 통해 얻을 수 있다.
형태소 분석
문서에 추출할 수 있는 특성은 대부분의 경우 단어를 기반으로 한다. 이를 위해 텍스트를 단어나 형태소 등의 단위로 쪼개는 것을 토큰화 (Tokenization)라고 한다. 토큰화를 통해 의미를 파악할 수 있는 단어의 최소 단위인 형태소를 분석하여 문장을 구성하는 어절들의 품사를 파악하고, 분석 목적에 따라 적합한 품사를 가지는 단어들을 추출한다.
특징 추출 및 변환
추출된 단어 중에서 분석에 사용될 의미 있는 단어를 선별하고, 이를 분석에 적합한 숫자 벡터로 변환한다. 여기에는 대/소문자 통일, 특수문자 삭제, 불용어 (Stop Word) 제거 등의 사전 작업이 포함된다. 수많은 단어의 우선순위를 파악하고, 이를 수치화하는 다양한 모형이 존재하는데, 대표적으로 9장에서 살펴본 바 있는 TF-IDF가 있다.
형태소 분석 및 특성 추출 및 변환 등의 전처리 과정을 거침으로써 비구조화된 문서 집합은 구조화된 단어 문서 행렬로 표현된다.
패턴 및 경향 분석
텍스트 데이터에 내재된 정보를 찾기 위해 최종 선정된 의미 정보인 단어 문서 행렬을 기반으로 패턴 및 경향 분석을 수행한다. 비정형 텍스트 문서를 분석 가능한 형태로 구조화하면 머신러닝 기법을 이용하여 문서를 분류하거나, 빈도 분석, 버즈 분석, 토픽 모델링 등 다양한 텍스트 마이닝 기법을 적용할 수 있다.
텍스트 마이닝의 실습을 위해 웹 스크래핑을 통한 자료 수집부터 빈도 분석, 버즈 분석, 토픽 모델링 등에 대해 순차적으로 진행해보자.
웹 스크래핑
기업 내부의 VOC DB처럼 자체적으로 보유한 텍스트 데이터가 있다면 웹 스크래핑과 같은 데이터 수집 기술이 불필요할 것이다. 그러나, 텍스트 마이닝의 중요한 전략적 목표 중 하나가 외부 빅 데이터에 대한 분석이므로 외부 데이터를 수집하여 활용하는 방법 역시 텍스트 마이닝에서 중요하다. 본 절에서는 외부 데이터를 텍스트 마이닝에 사용할 수 있도록 하기 위한 웹 스크래핑 기법에 대해 살펴보고자 한다.
텍스트 마이닝에 적용할 외부 데이터는 웹상의 다양한 곳에서 얻을 수 있으나, 매우 많은 양의 데이터가 존재하기 때문에 사람이 일일이 데이터를 수작업으로 수집하기에는 불가능하다. 따라서 웹 스크래핑 (Web Scraping)과 같은 컴퓨터 소프트웨어 기술을 활용해 자동으로 웹 문서에서 필요한 부분만 추출하는 과정이 필요하다. 파이썬에는 웹 사이트에 접속해 자료를 가져오기 위한 다양한 라이브러리들이 있어 쉽게 웹 스크래핑을 수행할 수 있다.
웹은 기본적으로 웹 페이지를 구성하고, 동작하게 하는 언어인 HTML (Hyper-TEXT Markup Language) 형태로 저장되어 있다. 따라서 웹 스크래핑을 하기 위해서는 해당 웹 페이지의 HTML 구조를 알아야 한다. 이를 위해 기본적인 HTML의 구조에 대해 먼저 알아보도록 하자.
HTML의 구조
HTML 문서는 HTML 요소 (Element)들로 이루어지며 각 요소의 식별자인 태그 (Tag), 그리고 각 태그의 정보를 나타내는 속성 (Attribute)으로 구성되어 있다. HTML 문서가 만들어지기 위한 기본 요소는 다음과 같다.
- html 요소: 문서 형태 선언
- head 요소: 문서 정보 표현
- body 요소: 문서 본문 표현
HTML 문서의 구조를 간단한 가상의 HTML 코드를 통해 살펴보면 다음과 같다.
<!doctype html>
<html>
<head>HTML 예제</head>
<body>
<h1>영화 정보</h1>
<p id=“movie_title”>기생충</p>
<p id=“director”>봉준호</p>
<p id=“release”>2019.09</p>
</body>
</html>
위 HTML 소스 코드의 첫 줄에 있는 <!doctype html>은 문서가 HTML임을 명시하는 DTD (Document Type Definition) 선언이다. DTD 선언 밑의 나머지 부분에서 ‘< >’로 둘러싸인 부분을 태그 (Tag)라고 하는데, 이는 HTML 요소의 의미를 확정하기 위해 붙이는 식별자 역할을 한다. 이 태그에 따라서 HTML의 문서 구조가 결정되며 웹 브라우저를 통해 보이는 화면이 달라진다. 태그는 시작 태그(< >)와 종료 태그(</ >)의 짝을 이루고 있으며, 시작 태그 안에는 부가적인 정보를 제공하는 속성 (Attributes)을 지정할 수 있다.

[그림 3] HTML 요소의 구조
이번 실습에서는 2020년 제92회 아카데미 시상식에서 감독상, 작품상, 각본상, 국제영화상 등 4개 부분을 석권하며 전 세계 영화인들의 관심을 듬뿍 받았던 영화 ‘기생충’에 대한 평점과 리뷰 정보를 사용하고자 한다. 평점은 텍스트 분석에 직접적으로 사용되지는 않지만, 텍스트 문서의 특성을 살펴보기 위해 추출한다. 데이터는 네이버 영화 사이트를 통해 추출할 것이다.
1) HTML 소스 코드 확인 및 정보 추출
웹 스크래핑을 하기 위해서는 리뷰 URL과 평점 및 리뷰 내용이 담긴 태그 정보가 필요하다. 우선 웹 브라우저에서 아래의 URL을 통해 기생충 평점 웹 사이트에 접속해보자.
https://movie.naver.com/movie/bi/mi/point.nhn?code=161967
〮HTML 코드로부터 리뷰 페이지 URL 추출
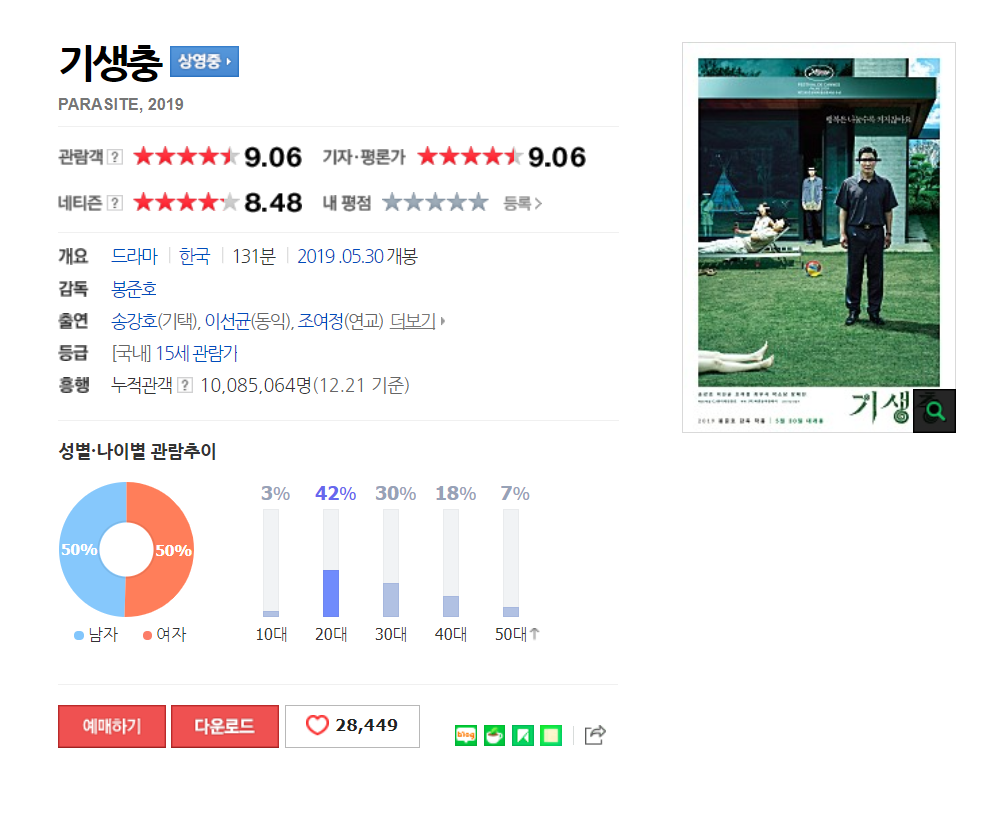

▶ 기생충 평점 웹 사이트에는 현재 총 33,881건의 관람객 리뷰가 등록되어 있으며, 한 페이지당 10건의 리뷰가 보이는 것을 확인할 수 있다. 모든 리뷰를 스크래핑하기 위해서는 모든 리뷰 페이지를 이동하면서 반복적으로 스크래핑 해야 한다. 이를 위해서는 각 리뷰 페이지의 URL 주소가 필요하고, 각 리뷰 페이지의 HTML 소스를 확인할 필요가 있다.
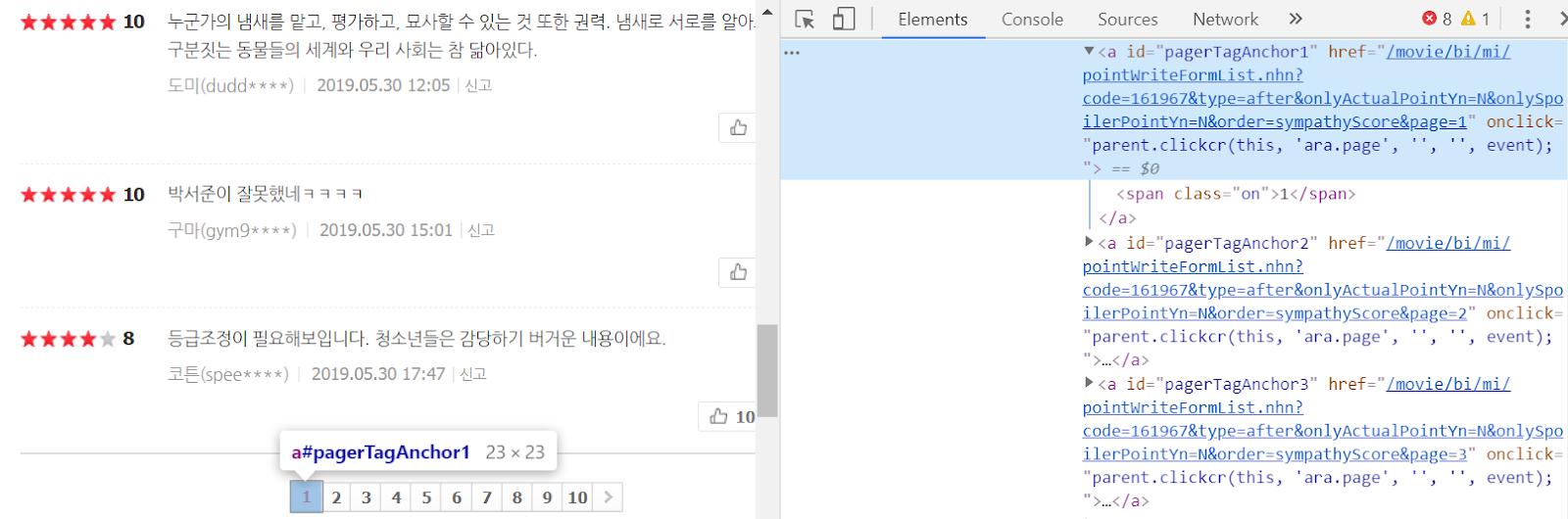
▶ 우선 각 페이지의 HTML 소스 코드를 보기 위해 페이지 번호 부분을 우클릭하여 [검사]를 클릭한다. 페이지 [1]에 대한 HTML 코드는 위 그림의 하늘색 영역에 해당한다. 이는 다음과 같다.

▶ 페이지 버튼은 href 속성을 가지는 a 태그로 감싸인 것을 알 수 있다. a 태그는 하이퍼링크를 설정하는 태그이며, href 속성은 클릭 시 이동할 URL을 나타낸다. 해당 URL에 접속하면 해당 관람객 평점만 존재하는 웹 사이트에 접속할 수 있으며, 페이지를 이동할 때마다 URL 맨 끝의 page 값이 달라지는 것을 확인할 수 있다.
〮평점 태그 정보 및 리뷰 태그 정보 확인
이제 평점과 리뷰의 태그 정보를 확인해보도록 하자.

▶ 첫 번째 리뷰의 소스 코드를 보면 하위 태그가 많아 복잡한 HTML 구조를 가지고 있으나, 해당 텍스트를 스크래핑하는 데 모든 태그를 다 알 필요는 없다. 평점 정보는 “star_score” class 속성을 가진 div 태그 안의 em 태그로, 리뷰 정보는 “_filtered_ment_0” id 속성을 갖는 span 태그로 둘러 쌓인 것을 확인할 수 있다. 평점의 경우 평점 외의 다른 텍스트도 동일한 em 태그로 구성되어 있기 때문에 상위 태그의 정보를 모두 알아야 하지만, 리뷰의 경우 속성값이 모두 다른 유일한 태그를 가지므로 상위 태그 정보까지 알 필요가 없다. 리뷰 10건에 대한 속성값을 모두 확인해보면, 0부터 9까지의 값을 순차적으로 갖는다. 가령 두 번째 리뷰의 경우 속성값은 “_filtered_ment_1”이다.
리뷰 스크래핑
이제 상기 과정을 통해 확인한 URL과 평점 및 리뷰 태그 정보를 이용하여 영화 기생충의 리뷰를 스크래핑해보자.
#1. 모듈 및 함수 불러오기
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
import re
#2. 리뷰와 평점을 담을 빈 리스트 생성
score = []
review = []
#3. 리뷰 스크래핑
for i in range(1, 1001) :
#3-1. HTML 소스코드 가져오기
base_url="https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=161967&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page="+str(i)
html = requests.get(base_url)
#3-2. HTML 파싱
soup = bs(html.text, 'html.parser')
#3-3. 평점 및 리뷰 텍스트 추출
for j in range(10):
score.append(soup.select('div.star_score > em')[j].text)
review.append(soup.find_all('span', {'id': re.compile('_filtered_ment_\d')})[j].text.strip())
#4. 하나의 데이터프레임으로 저장
df = pd.DataFrame(list(zip(review, score)), columns=['review', 'score'])
df.head()
끝으로 평점별 리뷰 수를 출력해보겠다
df['score'].value_counts()
This post was written based on what I read and studied the book below.
http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791195511747
댓글